
Tolosana vous offre désormais la possibilité d'effectuer une recherche de mots ou groupes de mots dans les ouvrages numérisés. L'OCR, Optical Character Recognition (soit la reconnaissance optique des caractères) est une technologie qui permet de convertir des documents scannés, au format image, en un texte qui peut être lu par programme informatique. Les ouvrages numérisés depuis la mi-janvier 2022 ont pu bénéficier de cette amélioration technique.
REPERAGE DES OUVRAGES OCERISES
Les ouvrages océrisés sont repérables dans Tolosana à différents niveaux :
1. Dans la liste de résultats après une recherche : les notices des ouvrages océrisés comprennent un badge ocr : 

2. Sur la notice des documents : les notices des ouvrages océrisés comprennent un logo ocr : 
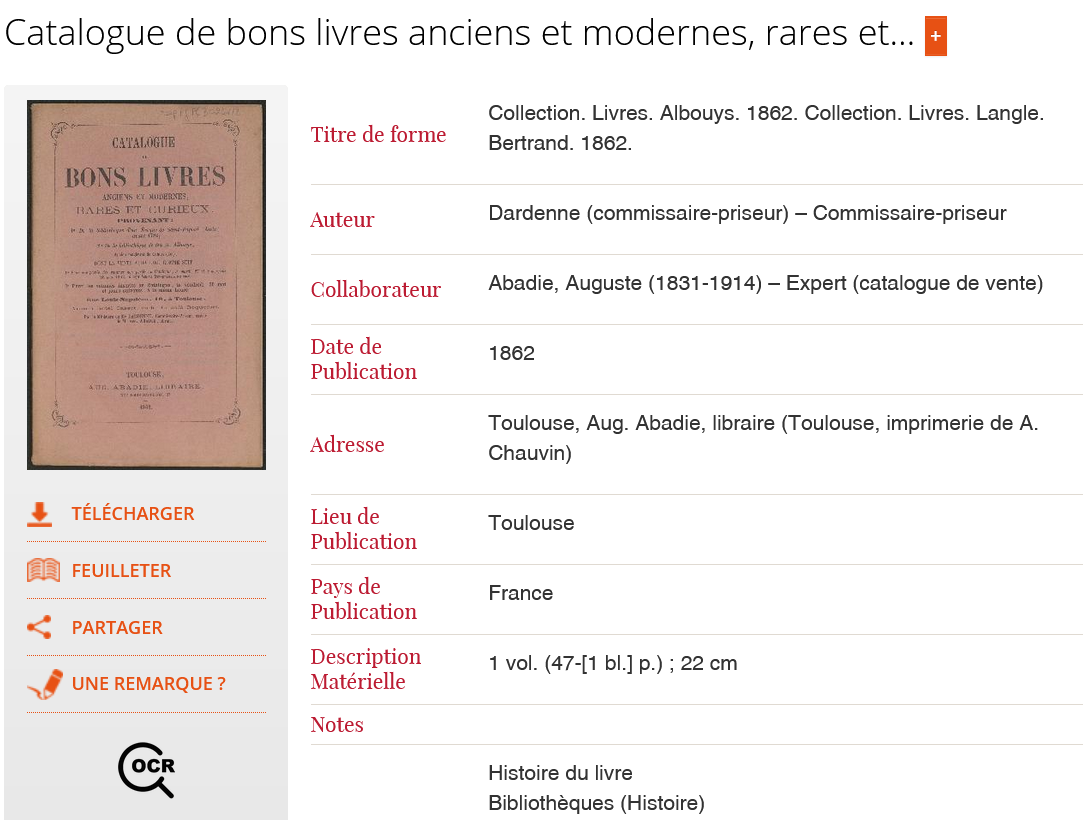
ACCES A LA FONCTION DE RECHERCHE PLEIN TEXTE
Depuis la liste de résultats ou bien depuis la notice du document numérisé :
1. Cliquez sur  pour télécharger le document complet et utilisez le raccourci clavier CTRL + F pour ouvrir la fenêtre de recherche .
pour télécharger le document complet et utilisez le raccourci clavier CTRL + F pour ouvrir la fenêtre de recherche .
Selon la visionneuse utilisée par votre navigateur, la fenêtre de recherche se trouvera généralement soit en haut et à droite soit en bas et à gauche de votre écran. Elle vous permettra de retrouver le mot ou groupe de mots souhaités et dans certains cas vous pourrez affiner votre recherche en cochant ou non des cases : surlignage de toutes les occurences (résultats de recherche), respect de la casse (majuscules/minuscules), respect des accents et des diacritiques (points, accents, tréma, cédilles), recherche exclusive de mots entiers.

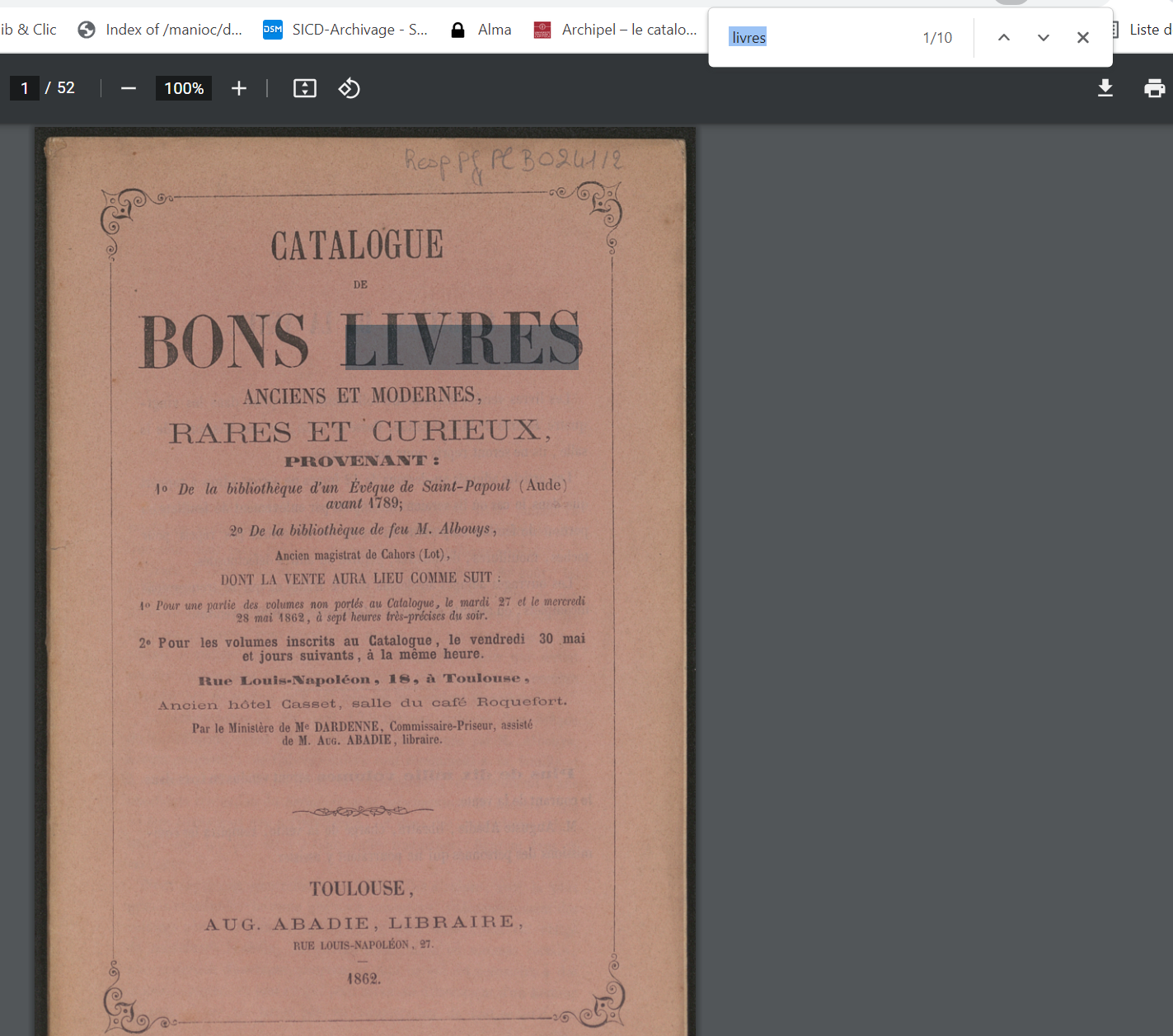
2. Tapez ensuite dans cette fenêtre le mot ou la suite de mots en rapport avec votre recherche, vous obtiendrez alors le nombre de fois où ils figurent dans le texte. Ceux-ci sont aisément localisables dans le texte grâce à un surlignage en couleur. Les deux petites flèches se trouvant à droite de la fenêtre de recherche vous permettront de naviguer rapidement d'un résultat à l'autre.

Si les logiciels d'OCR ont fait des progrès spectaculaires depuis quelques années, le résultat de la reconnaissance ocr est très variable en fonction de la nature bibliographique et physique des documents océrisés ; deux variables sont à prendre en compte :
- la lisibilité du document (défauts d'impression, vieillissement du papier, problèmes de migration d'encre ou de courbure de page)
- la langue, l'orthographe et la graphie du document
De ce fait les logiciels OCR ne sont pas toujours capables de reconnaître des caractères typographiques anciens comme par exemple le "s" long (à ne pas confondre avec la lettre "f") dont voilà un exemple 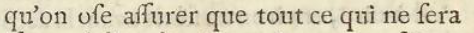 et que l'on rencontre fréquemment dans les ouvrages numérisés dans Tolosana jusqu'au XVIIIe siècle. Nous ne sommes malheureusement pas en capacité actuellement d'apporter des corrections manuelles sur l'OCR brut.
et que l'on rencontre fréquemment dans les ouvrages numérisés dans Tolosana jusqu'au XVIIIe siècle. Nous ne sommes malheureusement pas en capacité actuellement d'apporter des corrections manuelles sur l'OCR brut.
Pour toutes questions n’hésitez pas à nous contacter (cliquez sur « Nous contacter » en bas de la page).
Besoin d'aide ?
Cliquez pour : découvrir nos collections, trouver un document et comment optimiser votre consultation des documents
Posté le 15/02/2022 | Par Anne-Sophie Bouvet
